Configuring and working with Cloudfront Logs
Example of how to setup Cloudfront to log to S3, enable log rotation and how to download and work with combined Cloudfront log files.
Setting up logging on Cloudfront ¶
Cloudfront supports logging to an Amazon S3 bucket. Create the bucket first and then edit the Cloudfront distribution. Under the general tab specify a Bucket for Logs and also a log prefix.
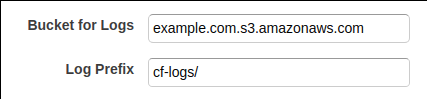
Once configured log files will be written to the S3 bucket as traffic flows through the Cloudfront distribution. Files are written as gzipped text files in the W3C extended log file format. This is good as they can be used with a variety of tools to analyse them.
More details on how AWS logs Cloudfront requests is available on the Cloudfront Developer Guide
Setting up log rotation on S3 ¶
Cloudfront writes logs to an S3 bucket which means that any of the features available on S3 can be used. Cloudfront logs each request so it is unlikely that there is a need to store this information forever and it also incurs a cost to store it. S3’s lifecycle feature can be used to remove files after a certain period.
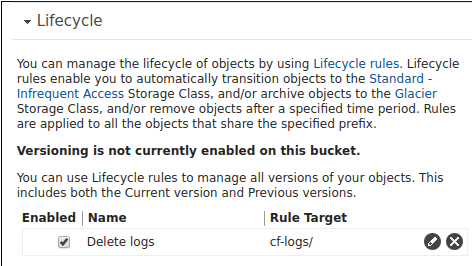
To enable lifecycle management open the S3 bucket and click on properties. Then
click on lifecycle. Then add a rule that targets the folder where the Cloudfront
logs are stored. In this example this is the cf-logs/ prefix.
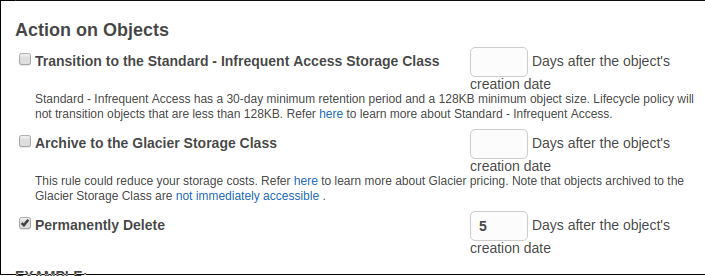
It is possible to choose to permanently delete files or to transition them to Amazon Glacier. In this example files are deleted after 5 days.
More information on lifecycle management is available on the S3 Developer Guide.
Fetching log files ¶
Now the log files are being written and being rotated they can be analysed. Amazon provide some services for interrogating logs but with some UNIX skill most requirements can be achieved by downloading the files.
To download the files here is a simple bash script to download the files,
combine them into a single file and removing any comments. The script depends on
the aws-cli tool that is readily available on all platforms.
More information on installing the aws-cli tool is available on the AWS CLI
User Guide
#!/usr/bin/env sh
BUCKET=$1
if [ "$1" ]; then
# Get the gzipped log files from aws
aws s3 sync s3://"$BUCKET" .
# Decompress, remove first two lines and combine
zcat ./*.gz | awk 'NR>2' >combined.log
# Cleanup by removing .gzip files
find "$(pwd)" ! -name 'combined.log' -name '*.gz' -type f -exec rm -f {} +
exit 0
else
echo "Error: no bucket name provided"
exit 1
fi
The script does the following:
- Reads the bucket name as the first argument
- Synchronises the current working directory with the specified S3 bucket
- Combines the gzipped log files into a single file
- Removes all files other than the combined file
- Decompresses the file
- Removes comments
The script is saved as aws-cf-logs. To fetch a combined log file is then as
simple as
aws-cf-logs example-bucket
ls
combined.log
The script is available as this gist. Feel free to fork, extend or improve it as you wish.
Working with the log files ¶
The log file is in a UNIX friendly standard format so it is easy to extract information from it using standard UNIX tools.
In the following example a file is generated with a list of 404 URLs ordered by frequency. This can be useful for finding broken links.
grep '404' combined.log | cut -f 8 | sort | uniq -c | sort -n -r
242 /apple-touch-icon.png
238 /apple-touch-icon-precomposed.png
54 /example-url/
40 /another-example-url/
...
In the following example a list of IP addresses is generated and sorted by frequency of occurrence. This can be useful for finding out bad bots.
cut -f 5 combined.log | sort | uniq -c | sort -n -r
1298 51.254.130.62
1846 216.244.66.240
1383 157.55.39.84
1325 68.180.228.227
...
In the following example the number of cache hits and cache misses is shown.
grep -c 'Hit' combined.log
19325
grep -c 'Miss' combined.log
8345
Further reading ¶
- AWS Cloudfront Developer Guide - AccessLogs
- AWS S3 Developer Guide - Lifecycle Management
- AWS CLI Developer Guide - Installing
Tags
Can you help make this article better? You can edit it here and send me a pull request.
See Also
-
Linux and Unix df command tutorial with examples
Tutorial on using df, a UNIX and Linux command for reporting file system disk space usage. Examples of viewing free disk space, viewing in human readable format, showing filesystem types and including and excluding specific filesystem types. -
Linux and Unix wget command tutorial with examples
Tutorial on using wget, a Linux and UNIX command for downloading files from the Internet. Examples of downloading a single file, downloading multiple files, resuming downloads, throttling download speeds and mirroring a remote site. -
Linux and Unix traceroute command tutorial with examples
Tutorial on using traceroute, a UNIX and Linux command for showing the route packets take to a network. Examples of tracing a route, using IPv6, disabling hostname mapping and setting the number of queries per hop.